
 ASCII ANSI Unicode UTF-8 UTF-16等字符编码的区别
ASCII ANSI Unicode UTF-8 UTF-16等字符编码的区别
 发表于 2023年4月26日 15:21
发表于 2023年4月26日 15:21
【字符编码】
字符编码就是将自然语言中的每个符号或者文字转换为二进制的形式存储到内存或者文件中。这里,我们先介绍几个概念:
字符集:所有字符和对应的码值的集合就是字符集,即所有字符编码的集合。字符集合就是码点空间,码点的介绍见下一条
码点:一个字符集合可以由一页或多页二维表来进行表示,每个字符可以根据通过行号+列号+页号来进行唯一的定位。这里可以把行、列以及页的编号看成三维空间的三条不同纬度的线,这三条线相交形成一个点,这个点就是码点。
码点编号:上面二所描述的从三个维度来定位一个码点,这三个维度对应组成一个数值集合,为这个集合分配唯一一个编号,这个编号成为码点值或者码点编号
平面:经过上面的讨论,我们发现了定位一个码点可以通过三个维度分别是行、列、页。在编码领域一般将页成为平面,就好像三位空间中,我们可以把行、列和页分别对应于X、Y和Z轴,则相同的Z对应形成一个平面,这个平面就是字符编码中的平面。在unicode中按照前期规划的规则一般分为0~16总计17个平面,每个平面可以容纳216=65536
216=65536
个码点,因此unicode字符集中一共有17∗65536=111411217∗65536=1114112个字符
下面,我们将根据计算机字符编码发展史的顺序,分别介绍几种编码格式
【ASCII】
ASCII,American Standard Code for Information Interchange,中文名称美国信息交互标准代码。是由美国相关机构定义的用来表示英文符号(比如A)和一些其他特殊符号(比如$)以及控制符(比如\n,换行符)。这些字符编码用一个字节进行表示,其中只用到了前七位,这7位数据中对应的字符集中包含了26个小写英文字母、26个大写英文字母、10个数字、32个符号、33个控制符、1个空格总计127个代码。
另外多说一些,在早起的ASCII数据传输的时候,剩余没用的那个高位。在标准的ASCII中用来做奇偶校验位。奇偶校验位主要用来进行一定长度上的数据传输正确性的校验
奇偶校验:一般分为两种即奇校验和偶校验。奇校验规定数据中对应的二进制值中的1的数量必须为奇数,如果不是奇数则在最高位添1让整个数据的1的数量为奇数;偶校验同理。http://www.jsons.cn/gbkcode/
【ANSI】
当信息技术因为互联网的发展,从美国本土走向世界的时候。为了在计算机上显示不同国家当地的文字,方便不同国家的使用。这个时候,上面讨论的ASCII编码就不满足需求了。因为比如中文中光常用字就3500个,这个集合远远大于一个字节可以存储的范围。因此,需要一个更大的字符集来进行表示。
更大的字符集就意味着,每个码值的存储空间需要扩展(这里面先不考虑编码存储的事情)。这个时候考虑到对于ASCII的兼容,依旧使用0x00~0x7F的范围来表示ASCII字符集内的字符。超过这个范围外的字符,用两个字节来表示。这两个字节的范围都是0x80~0xFF。
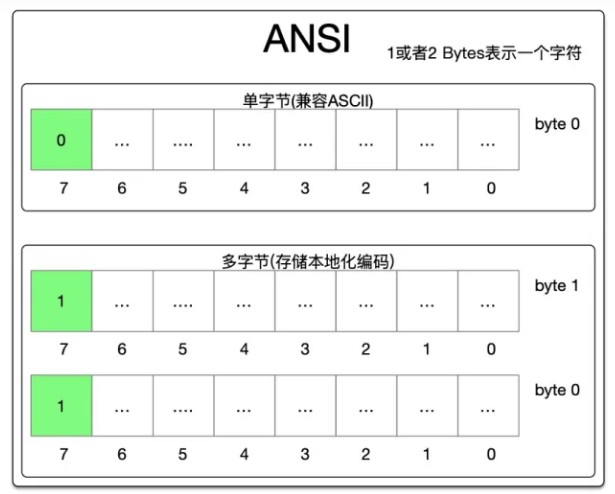
上图,是ANSI编码的示意图,其中绿色的部分代表固定的值,通过这些固定的值,可以识别出来一个字符是单字节表示的还是多字节表示的:
当一个字节数据的最高位是0的时候代表是单字节,按照ASCII表进行编码的
当一个字节数据的最高位是1的时候,代表是本地化扩展字符,需要用将相邻的两个字节组成一个整体,来进行码值求取,得到的码值对应的本地化的字符集可以得到相应的字符是什么
下面,以ASCII表中的A和中文哈来示例。这里面是在windows10下的VS2017的控制台开发环境中进行测试,该控制台项目的字符编码设置为多字节的。通过notepad++来在文本文件中输入A哈。然后在程序中对文件进行读取打印输出其对应的二进制值(16进制表示)。得到的这两个字的输出结果为
0x41 0xb9 0xfe
其中41对应的是ASCII表中的字符A,0xb9fe对应的就是gbk编码表(测试环境windows 10使用的本地化编码的字符集就是gbk)字符就是哈。这里贴出测试使用的gbk在线查找表。
下面,我们讨论一下程序中关于ANSI的存储问题。在C++程序中,我们通常使用char数组作为最基本的存储数据结构,来对以0为结尾的字符串进行存储。根据上图所示,由于其单字节和多字节的编码信息是根据最高位是否为1来设计的。所以在多字节模式下保证了每一个字节都不会是0,这就保证了ANSI的字符串依然可以使用以0为结尾的char数组的形式进行存储
【Unicode】
ANSI其实就是ASCII码表加本地化的编码表,本地化的编码表跟区域地点不同编码表不同。比如中国和日本的本地化编码表就是不同的,在进行编码解析的时候,超出ASCII编码表范围的部分,需要采用对应的本地化编码表进行编码。也就是说在进行数据解码的时候,需要用正确的编码表进行解码
这就面临一个问题,两个本地化编码表不同的系统,无法对对方的编码进行有效的解码。这就造成了不同的本地化系统之间进行数据交互的时候比较困难,容易出现乱码的情况
为了解决不同本地化编码表的问题,就引入了Unicode编码。
Unicode码称为万国码、单一码,是将世界上所有国家的字符编码进行统一的编码。Unicode是一个字符集,给所有的字符分配一个码值。这里面只是分配码值,而不是最后的编码实现,编码的实现有很多不同的方式如utf-8、utf-16、utf-32。
在对所有的语言和字符进行一个统一的编码之后,这样不同的本地化字符集之间也可以进行畅通的沟通。目前我们使用的标准ucs-2的unicode的形式进行定义,该形式采用两个字节来存储一个字符,两个字节一共可以存储2^16=65536,65536个字符,可以涵盖大多数语言,也是常用的存储方式(这就是现在绝大多数系统采用16位长度宽wchar数组来对unicode字符串进行存储)。
为了留下其他特别不常用的偏门的字符编码问题,还有一个ucs-4的形式,这种形式是采用4个字节进行存储
上面的unicode在具体的软件内存中,常规情况下是采用2个字节的宽字符来存储unicode来进行存储的。下面我们讨论一下wchar的相关细节
宽字节
在操作系统或者是标准库中,一定看见过或者是用过wchar这个类型(或者是包含这个关键字的类型,在标准库中对应的是std::wstring)。
这个类型是用来存储unicode码的,通过宽字符来直接存储unicode的值。采用这样的存储方式有下面两个问题:
由于直接存储的码值,所以在进行解码的时候不需要分析字符流,可以进行解码,这样效率较高
直接存储同时也带来了另外一个问题,就是内存空间占用大。比如ascii的码值本来可以使用一个字节进行存储,在这里依然需要采用两个字节进行存储。所以在一些在意数据大小的场景下,一般不采用这种存储方式,采用比如utf-8的编码实现来进行网路数据传输,这样可以节省网络流量。但是在应用程序本地进行界面显示,可以直接采用unicode进行存储
在C++标准中,并没有规定wchar这个类型的长度,这个长度是由编译器的具体实现。一般情况下编译器的实现都是2个字节的版本,采用的ucs-16的标准。
这里采用2字节进行存储,就可以满足目前的需求,并且使用两字节进行一个字符的存储,可以保证以0为结尾的字符规则依然有效。也就是两个字节对应的值是0的时候判定为字符串的结尾,这样可以兼容以前的窄字节的字符串的相关算法
【UTF】
UTF,Unicode Transformation Format,中文含义unicode转换格式。从中文名称能看出来,utf就是unicode的一种编码实现。目前
主要有utf-8、utf-16和utf-32这三种,下面我们就对这三种进行探讨。
【UTF-8】
UTF-8采用可变字节的形式进行编码,使用1到4个字节进行存储。最下编码单元是1个字节,所以对空间的利用高,比较适合网路传输。广泛应用于网络传输比如web采用的就是utf-8对数据进行编码传输
下面,我们看一下utf-8字符编码是如何对unicode的码值进行编码的。如下图所示,UTF-8按照码值的存储大小分为单字节符号存储和多字节存储。
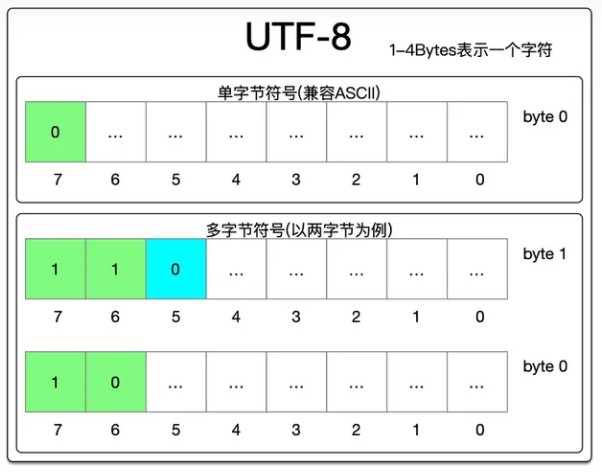
单字节存储,即采用一个字节代表一个码点,采用最高位为0来进行标识。当字符流中,字节的最高位为0的时候,可以代表这个字节中存储了一个码点,后边剩余的7位存储这这个码点对应的码值。单字节符号的存储是兼容ASCII字符集的,这也是utf-8的优点
多字节存储,超出ASCII字符集之外的。需要采用多个字节进行存储。如上图的下半部分所示。在utf-8中可以采用2到4个字节进行码值的存储。以上图中的两个字节存储为例,高位字节的(大端序为例)的高两位存储两个1用来代表这是一个两字节存储,后边跟着一个0用来和后边的数据进行隔开。后边跟着的另外一个低位的字节,前两位以1和0进行开头,用来标识这是后续字节,并且最高位固定为1也可以和单字节存储区分开(单字节存储最高位固定为0)
【UTF-16】
UTF-16采用2字节或者4字节进行存储,相比较于utf-8,采用这种方式,可以加快解码速度。但是带来了两个问题,就是数据的存储空间变大和无法兼容ASCII。
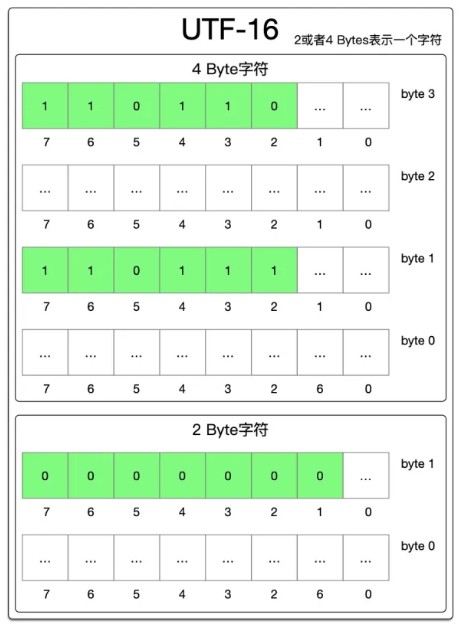
2字节字符:对于字符在unicode中码值在0x00000~0x10000的范围内的时候,采用2字节进行存储来直接存储unicode对应的码值。对于大于此范围的码值
4字节字符:对于字符在0x00000~0x10000范围外的时候,采用4字节进行存储。4字节进行存储的时候,从高往低(按照大端序)来字节分别编号为3、2、1、0。字节3的高6位从高到低依次是110110、字节1的高6位从高到低依次是110111。其他剩余位从高到低依次填入该字符对应的unicode码值对应的二进制位
【UTF-32】
UTF-32是每个码点都用4字节进行存储,存储的就是unicode对应的值,没有进行编码直接存储的。


 返回列表
返回列表